
Today's large language models are masters of trivia but struggle with consistency and self-knowledge. The next frontier in AI research aims to build models that are not just correct, but coherent, efficient, and grounded in reality.
Summary
Large language models (LLMs) have achieved remarkable feats of knowledge recall, yet they remain brittle. They can answer obscure historical questions but will confidently contradict themselves moments later, revealing a shallow understanding. This reflects two core deficits: a lack of factual coherence and poor 'metacognition'—an inability to know what they know. The next wave of AI research is moving beyond the simple pursuit of accuracy to address these deeper challenges. Researchers are developing novel training methods that reward models for internal consistency and honest self-assessment. Simultaneously, they are re-engineering the fundamental architecture of AI, moving beyond the dominant Transformer to create more efficient and expressive systems. Finally, by exploring the surprising, emergent connections between language and vision, scientists are working to ground these models in a richer, multimodal understanding of the world. This shift promises not just smarter AI, but more reliable and trustworthy systems.
Key Takeaways; TLDR;
- Today's LLMs are optimized for accuracy, which can lead to factual inconsistencies and uncalibrated confidence.
- A key failure is in 'metacognition,' where models don't know what they know and confidently assert contradictory claims.
- New research focuses on training for 'coherence' by having models self-critique their own outputs to build a consistent set of beliefs.
- Improving self-awareness involves rewarding models not just for being right, but for accurately assessing their own confidence (i.e., being uncertain when wrong).
- The Transformer architecture, while revolutionary, has efficiency and expressiveness limitations, especially for very long sequences.
- Future architectures are likely to be hybrids, combining standard attention with more efficient alternatives like state-space models (e.g., Mamba).
- Text-only LLMs surprisingly learn representations of the world that align with vision models, suggesting a shared underlying structure of knowledge.
- Strengthening the link between language and vision, for example through 'cycle consistency,' can create more grounded and descriptive AI models. Large language models (LLMs) are masters of a peculiar kind of intelligence. Ask a state-of-the-art model an obscure question of mid-century South Indian politics—say, “Was S. Chellapandian first appointed as speaker of the Madras legislative assembly in 1962?”—and it might correctly answer “Yes,” even providing a numerical confidence score if asked . This is a stunning display of knowledge recall, performed without a web search, drawing only on the patterns embedded within its trillions of training tokens.
But this impressive facade can be surprisingly brittle. Ask the same model if Chellapandian was appointed in 1937, and it might again answer “Yes,” this time with even higher confidence. This simple exchange reveals two fundamental flaws lurking beneath the surface of today's AI: a failure of factual consistency and a failure of self-awareness.
The model has made a factual error, but more importantly, it has demonstrated a profound lack of what we might call metacognition—it doesn’t know what it knows. The pursuit of raw accuracy has created systems that can ace a trivia contest but fail a basic test of logical coherence. The future of AI depends on moving beyond this paradigm, building models that are not just accurate, but also coherent, efficient, and truly grounded in the world they describe.
Coherence vs. Incoherence: The next generation of AI is being trained not just for factual recall, but for maintaining an internally consistent model of the world.
The Illusion of Knowledge: When LLMs Contradict Themselves
The first error in the Chellapandian example is a breakdown in the model's understanding of the world. A person cannot be appointed to the same unique position for the first time on two different dates. This reflects a failure to maintain an internally consistent world model—a coherent representation of facts and their relationships.
The second error is more subtle. By assigning high confidence to two mutually exclusive statements, the model reveals a flawed self-model. It lacks an understanding of its own knowledge and limitations. An expert, when uncertain, expresses that uncertainty. An LLM, trained to produce the most probable next word, often defaults to a tone of unearned authority.
These aren't edge cases; they are expected outcomes of our current training methods. For decades, the primary goal in language modeling has been accuracy: correctly predicting the next word or giving the right answer to a question . But as models become more powerful, the flaws in this single-minded approach become more apparent. A model, by definition, is a useful abstraction of reality. While human-built scientific models are often incomplete, their great power comes from their internal coherence. They provide consistent answers within their domain of expertise. For AI to become a truly reliable tool, it must learn to do the same.
From Accuracy to Coherence: A New Training Paradigm
What if, instead of just optimizing for accuracy, we explicitly trained models to be coherent? Researchers at MIT are exploring novel techniques that do just that, focusing on improving both the model's grasp of the world and its understanding of itself.
Teaching Models to Self-Correct
One promising, and surprisingly simple, unsupervised method aims to enforce factual consistency. The process works in a few steps:
- Generate: Prompt an LLM to write down everything it knows about a specific topic, without initially worrying about contradictions.
- Critique: Use the same LLM to analyze this generated text. The model's task is now much simpler: identify which statements contradict each other and which ones offer mutual support.
- Select: The model then identifies the largest subset of facts that are both internally coherent and most likely to be true.
- Retrain: Finally, the model is fine-tuned on its own curated output, learning to assign a higher probability to the coherent set of statements and a lower probability to the discarded ones.
Remarkably, this process, which provides the model with no new factual information from the outside world, dramatically improves its performance on fact-checking benchmarks. By forcing the model to reconcile its own knowledge, it builds a more robust and internally consistent world model .
Rewarding Intellectual Honesty
To address the failure of metacognition, another line of research rethinks the reward systems used in training. Standard reinforcement learning techniques often inadvertently encourage overconfidence. A model gets a high reward for a correct, confident answer, but the penalty for a wrong, confident answer isn't structured to sufficiently discourage it.
Drawing on classic ideas from decision theory, researchers have modified the scoring function. The new system still rewards correct, confident answers. However, it also rewards the model for being wrong but expressing low confidence. This incentivizes a form of intellectual honesty. The model learns that it's better to admit uncertainty than to bluff .
This skill, known as calibration, is crucial for trustworthy AI. A well-calibrated model's confidence score is a meaningful indicator of its likely accuracy . The most surprising finding is that this skill generalizes. When trained to self-assess on one set of problems, the models become better calibrated and more accurate on entirely new, unseen tasks. They learn the general skill of knowing what they don't know.

The architectural bottleneck: The Transformer's quadratic complexity makes it inefficient for very long sequences, driving the search for linear-time alternatives like state-space models.
Beyond the Transformer: Building a Better Engine for Intelligence
The dominant recipe for modern AI involves three ingredients: massive datasets, a compression-based learning objective, and a model architecture called the Transformer . While data and objectives are crucial, the architecture is the ingredient that unlocked the current revolution.
To understand its importance, consider a 2007 paper from Google titled “Large Language Models in Machine Translation” . The researchers trained a model on two trillion tokens of text—a scale comparable to today's systems. Yet, it produced no ChatGPT. The reason? The architecture was based on simple n-gram lookup tables. The leap from 2007 to today was not just about more data, but about a fundamentally better architecture: the Transformer, introduced in the 2017 paper “Attention Is All You Need” .
But is the Transformer the final word in AI architecture? Growing evidence suggests it is not.
The Limits of Attention
The Transformer’s core innovation is the “attention mechanism,” which allows the model to weigh the importance of all previous tokens when generating the next one. This is incredibly powerful, but it has two major drawbacks:
- Inefficiency: The attention mechanism’s computational cost grows quadratically with the length of the input sequence. For every new token, it must look back at the entire history. This is manageable for a few thousand tokens but becomes prohibitively expensive for processing a million-line codebase or a full genome sequence.
- Inexpressiveness: Despite its power, the Transformer architecture has provable limitations. For example, a single-layer Transformer struggles with simple “state tracking” tasks, like keeping track of which item is in which box after a series of swaps . These are the kinds of logical operations fundamental to understanding code or complex causal chains.
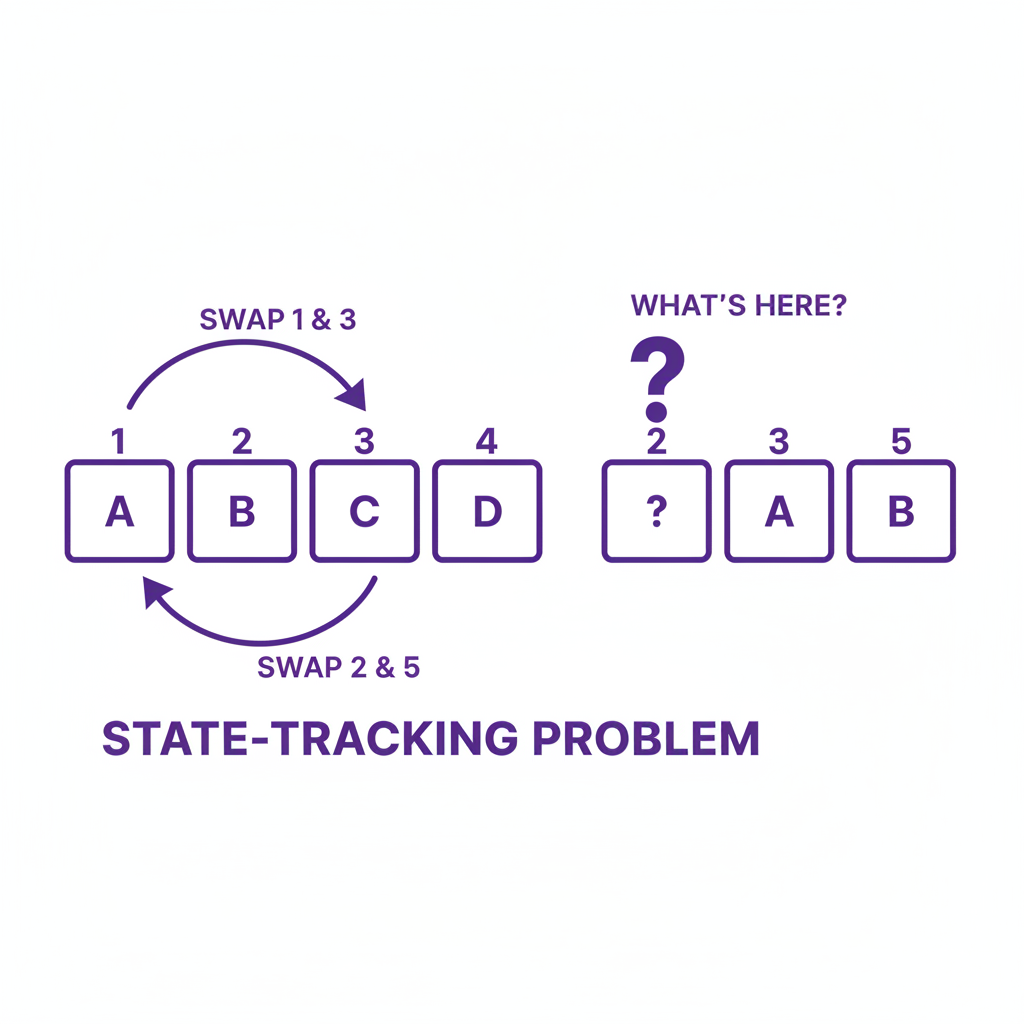
Simple tasks like state tracking can be surprisingly difficult for standard Transformer architectures, highlighting limitations in their expressive power.
The Rise of Hybrid Architectures
These limitations have spurred a search for alternatives. One of the most promising directions is a family of models that includes linear attention and state-space models (SSMs), such as the recently influential Mamba architecture . These models can be formulated to behave like recurrent neural networks (RNNs), processing sequences with a fixed-size memory state. This makes them far more efficient, allowing them to handle virtually unlimited context lengths with linear, rather than quadratic, scaling.
While early versions of these models sacrificed some expressiveness for efficiency, recent work has focused on closing that gap. The near future of AI architecture is likely to be hybrid, mixing the proven power of global attention for some tasks with the efficiency of linear or state-space layers for others. State-of-the-art open-source models, like Alibaba's Qwen2, are already incorporating these architectural innovations to push the boundaries of performance and efficiency . In the longer term, we may see dynamic architectures that allocate computational resources based on the complexity of the input, rather than applying the same brute-force computation to every single token.
Does a Text-Only AI Dream of Electric Sheep?
Another critical frontier is grounding models in the real world. This brings up a classic philosophical puzzle known as the symbol grounding problem: how does the word “apple” become connected to the actual, physical fruit? Can a model trained only on text, which has never seen an apple, truly understand what one is?
Intuitively, it seems possible. Human language is rich with sensory descriptions. A fantasy novel describes a “scaly, green, shiny dragon,” and a reader who has never seen a dragon can form a vivid mental image. Text is not divorced from the physical world; it is a reflection of it.

The Symbol Grounding Problem: Research shows that text-only models naturally learn representations that align with the visual world, bridging the gap between words and their meanings.
Research confirms this intuition in a striking way. In one experiment, scientists took a text-only model (BERT) and analyzed the internal representations, or embeddings, it had learned for color words. When they mapped these embeddings in 3D space, they found that the model had spontaneously organized the colors in a structure remarkably similar to the CIELAB color space, a model based on human visual perception . Without ever seeing a single pixel, the model learned a geometry of color that mirrors our own.
Further research shows this is a general principle. As language models get better at their primary task of predicting text, their internal representations become more aligned with the representations of vision models trained on images . And as vision models get better, they align more with language models. It seems that both are converging on a shared, underlying structure of how concepts relate to one another, because they are both modeling the same world.
Forcing a Deeper Connection: Cycle Consistency
This natural alignment isn't perfect, but it can be explicitly strengthened. One powerful technique is to enforce cycle consistency. An image captioning model might see a photo and output a simple, uninspired description: “a cup of coffee.” If you feed that text into an image generation model, you might get a generic picture that looks nothing like the original.
Cycle-consistent training aims to fix this. The goal is to train the captioning model to produce a description so visually rich that it can be used to reconstruct the original image. The model is rewarded when the generated image from its caption is similar to the source image . This forces the language side of the model to become a better, more precise observer of the visual world, learning to describe patterns, colors, and lighting in detail.
Why It Matters: The Path to More Reliable AI
The single-minded pursuit of accuracy has brought AI to its current heights, but it will not carry it to the next level. The future of LLMs lies in a more holistic approach that values coherence, calibration, efficiency, and grounding.
By training models to be internally consistent and aware of their own limitations, we can build systems that are not just knowledgeable, but also trustworthy. By developing new architectures that scale efficiently, we unlock the ability to apply AI to complex, long-form problems in science, engineering, and beyond. And by connecting language to other modalities like vision, we create models that have a richer, more robust understanding of the world.
This research represents a shift from treating AI as a pure pattern-matching engine to engineering it as a more reliable partner for human thought and creativity. The goal is not just an AI that can give the right answer, but one that understands why it's right and knows when it might be wrong.
I take on a small number of AI insights projects (think product or market research) each quarter. If you are working on something meaningful, lets talk. Subscribe or comment if this added value.
References
- Tamil Nadu Legislative Assembly: The Speakers - Government of Tamil Nadu (gov, 2023-01-01) https://assembly.tn.gov.in/archive/3rd_assembly/speakers.htm -> Verifies the factual claim used in the opening example that S. Chellapandian was the Speaker of the Madras (now Tamil Nadu) Legislative Assembly starting in 1962.
- A Statistical Approach to Language Translation - IBM Research (org, 2011-01-01) https://www.research.ibm.com/compsci/the-science-behind-watson/the-science-behind-watson-a-statistical-approach-to-language-translation.html -> Provides historical context on the long-standing focus on statistical accuracy (next-word prediction) in language modeling, dating back to its early days.
- Self-Correction and Self-Consistency: The Future of LLM Training? - AssemblyAI (news, 2024-03-20) https://www.assemblyai.com/blog/self-correction-and-self-consistency-the-future-of-llm-training/ -> Explains the concept of training LLMs for consistency by having them generate, critique, and refine their own outputs, similar to the method described in the talk.
- Teaching Models to Express Their Uncertainty in Words - Google AI Blog (org, 2023-06-21) https://ai.googleblog.com/2023/06/teaching-models-to-express-their.html -> Discusses research on training models to produce calibrated verbal uncertainty, which aligns with the concept of modifying reward functions to improve metacognition.
- Beyond Confidence Scores: The Nuances of AI Model Calibration - QualZ.ai (news, 2024-05-15) https://qualz.ai/beyond-confidence-scores-the-nuances-of-ai-model-calibration/ -> Provides a detailed explanation of what model calibration is, why it's important for trust and reliability, and why simple confidence scores can be misleading.
- The AGI Recipe: A Conversation with Dr. Yoon Kim - MIT (video, 2024-10-01)
-> The source video for the concepts presented in the article, including the 'AGI recipe' and research vignettes from MIT professors. - Large language models in machine translation - ACL Anthology (journal, 2007-06-28) https://aclanthology.org/D07-1090.pdf -> The 2007 Google paper cited to illustrate that large-scale data existed before modern architectures, highlighting the crucial role of the Transformer.
- Attention Is All You Need - arXiv (whitepaper, 2017-06-12) https://arxiv.org/abs/1706.03762 -> The seminal paper that introduced the Transformer architecture, which became the foundation for modern LLMs.
- The Expressive Power of Transformers with Chain of Thought - arXiv (whitepaper, 2023-05-22) https://arxiv.org/abs/2305.13093 -> This paper analyzes the limitations of Transformers, including their struggles with algorithmic tasks like state tracking, which supports the claims made about architectural weaknesses.
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces - arXiv (whitepaper, 2023-12-01) https://arxiv.org/abs/2312.00752 -> The foundational paper for the Mamba architecture, a leading example of a state-space model that offers an efficient alternative to the Transformer.
- Qwen2: The new state-of-the-art open-source LLM - Qwen Team, Alibaba Cloud (org, 2024-06-06) https://qwen.ai/blog/qwen2 -> Announces the release of a state-of-the-art open model that uses architectural innovations, serving as a real-world example of the trend toward new and hybrid architectures.
- Can Language Models See Colors? - ACL Anthology (journal, 2021-04-19) https://aclanthology.org/2021.eacl-main.143/ -> The specific research paper that found BERT's internal representation of color words mirrors the human perceptual CIELAB color space.
- The geometry of truth: Emergent linear structure in large language models - arXiv (whitepaper, 2023-10-10) https://arxiv.org/abs/2310.06824 -> This paper from Phillip Isola's group provides evidence for the claim that language and vision models' representations become more aligned as the models improve.
- Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks - arXiv (whitepaper, 2017-03-30) https://arxiv.org/abs/1703.10593 -> The foundational paper on CycleGAN, which introduced the concept of cycle consistency as a powerful unsupervised training signal, the same principle applied in the image captioning example.
Appendices
Glossary
- Metacognition: Literally 'thinking about thinking.' In the context of AI, it refers to a model's ability to assess its own knowledge, limitations, and confidence levels.
- Calibration: A property of a well-behaved model where its predicted confidence score accurately reflects the true probability of it being correct. A model that says it's 80% confident should be right about 80% of the time.
- Transformer Architecture: The dominant neural network architecture for LLMs, introduced in 2017. Its key feature is the 'attention mechanism,' which allows it to weigh the importance of different words in the input sequence.
- State-Space Model (SSM): An alternative to the Transformer architecture that processes sequences linearly, making it highly efficient for very long contexts. Mamba is a prominent example.
- Symbol Grounding: A philosophical and technical problem in AI concerning how symbols (like words) in a system get their meaning by being connected to the real-world objects or concepts they refer to.
Contrarian Views
- The 'scaling hypothesis' suggests that many of the current limitations of LLMs, including inconsistency and poor reasoning, will be resolved simply by training even larger models on more data, without needing fundamental changes to architecture or training objectives.
- Some researchers argue that true 'understanding' or 'grounding' is impossible for a system trained only on text, and that models will always be 'stochastic parrots' merely mimicking patterns without genuine comprehension, regardless of their performance.
- Focusing on complex new architectures may be a distraction. The simplicity and parallelizability of the Transformer are what made it so successful, and moving to more complex recurrent models could slow down progress by making training more difficult.
Limitations
- The research presented on coherence and calibration represents promising new directions but is not yet standard practice in the training of most large-scale commercial LLMs.
- While new architectures like Mamba show great promise in efficiency, the Transformer still often holds a performance edge on many standard benchmarks, and the trade-offs between different architectures are still being actively explored.
- The alignment between language and vision models is a statistical correlation. It does not definitively prove that the language model has human-like 'understanding' of visual concepts.
Further Reading
- Sparks of Artificial General Intelligence: Early experiments with GPT-4 - https://arxiv.org/abs/2303.12712
- The Illustrated Transformer - https://jalammar.github.io/illustrated-transformer/
- On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? - https://dl.acm.org/doi/10.1145/3442188.3445922
Recommended Resources
- Signal and Intent: A publication that decodes the timeless human intent behind today's technological signal.
- Thesis Strategies: Strategic research excellence — delivering consulting-grade qualitative synthesis for M&A and due diligence at AI speed.
- Blue Lens Research: AI-powered patient research platform for healthcare, ensuring compliance and deep, actionable insights.
- Outcomes Atlas: Your Atlas to Outcomes — mapping impact and gathering beneficiary feedback for nonprofits to scale without adding staff.
- Qualz.ai: Transforming qualitative research with an AI co-pilot designed to streamline data collection and analysis.