
We have 900 million weekly users and trillion-dollar infrastructure, yet the "God in a box" still lacks a job description.
Summary
As we approach the end of 2025, the artificial intelligence landscape presents a striking contradiction. On one hand, adoption metrics are staggering: ChatGPT alone boasts nearly 900 million weekly active users, and hyperscalers are pouring over $300 billion annually into infrastructure. On the other, a "utility gap" persists. While the technology has achieved massive distribution, it has not yet anchored itself into the daily workflows of the broader economy in the way the internet or mobile phones did.
This essay explores the structural and economic realities of the current AI wave. It argues that we are in a "deployment paradox" where raw capability outpaces our understanding of how to mold it into products. We examine the precarious economics of the infrastructure build-out, the surprising resilience of incumbents like Google and Meta, and the critical shift from "training scaling" to "inference reasoning." Ultimately, the revolution will not be defined by the models themselves, but by the unglamorous work of unbundling them into specific, reliable software solutions.
Key Takeaways; TLDR;
- The Utility Gap: Despite 900 million weekly users, most engagement remains casual. The technology is widely known but not yet deeply integrated into non-technical professions.
- The Capex Gamble: Hyperscalers are spending $300B+ annually on infrastructure. This "build it and they will come" strategy risks a massive capital overhang if revenue doesn't follow quickly.
- Incumbents are Winning: Unlike the internet era, which birthed new giants, AI currently reinforces existing aggregators (Google, Meta) who use it to optimize ads and search.
- The Interface Problem: The "chatbot" is a weak interface for complex work. The next wave of value requires wrapping models in specialized GUIs, not just better prompts.
- Scaling Uncertainty: We don't know the physical limits of LLMs. If scaling laws plateau, the industry must pivot from "bigger models" to "better inference" and specialized agents.
The 900-Million-User Paradox
By late 2025, the numbers have become impossible to ignore. ChatGPT reportedly serves between 800 and 900 million weekly active users . To put that in perspective, it took the mobile phone industry a decade to reach similar ubiquity. And yet, a strange dissonance hangs over this achievement. If you look closely at those users, a pattern emerges: a small minority uses the tool for hours every day—coding, writing, analyzing—while the vast majority visits sporadically, fascinated but fundamentally unsure of what to do with it.
We have achieved distribution without definition. Five times as many people have accounts as have actual daily use cases. This is the central paradox of the current AI moment: we have built a "God in a box," a machine capable of PhD-level reasoning, yet for the average accountant, lawyer, or logistics manager, it remains a novelty rather than a necessity.
The term "AI" itself has become a moving target, much like "technology" or "automation." Once a capability works reliably—like a database or a spam filter—we stop calling it AI. It recedes into the background. What remains labeled "AI" is the frontier: the new, the scary, and the undefined. We are currently trapped in a cycle where the technology is either "already here" (and therefore just software) or "five years away" (and therefore science fiction). The middle ground—reliable, transformative daily utility—is still being built.
The Infrastructure Casino
While users figure out what to do with the software, the technology industry has made the most expensive bet in industrial history. The capital expenditure (CapEx) numbers are staggering. In 2025 alone, the major hyperscalers—Microsoft, Amazon, Google, and Meta—are projected to spend over $300 billion collectively on data centers and chips .
This spending is driven by a game theory dynamic rather than immediate ROI. For a company like Google or Meta, the risk of under-investing and missing the platform shift is existential, whereas the risk of over-investing is merely financial. As Mark Zuckerberg has noted, if they build too much capacity, they can theoretically use it for something else . But this logic has a flaw: if everyone overbuilds because they assume capacity is fungible, and the demand doesn't materialize, the value of that capacity collapses.

The Capex Overhang: The industry is investing hundreds of billions in anticipation of demand that has not yet fully materialized.
We have seen this movie before. In the late 1990s, telecom companies laid millions of miles of fiber-optic cable, anticipating a bandwidth explosion that wouldn't arrive for another decade. The crash was brutal, but the infrastructure remained, eventually enabling the modern internet. Today, we are pouring concrete and silicon into the ground at a rate that demands a $600 billion annual revenue stream just to break even . Currently, the actual revenue from generative AI—outside of hardware sales—is a fraction of that. We are building the railroads before we have invented the locomotive, let alone the freight.
The Incumbent's Fortress
In previous platform shifts, the new technology created new giants. The internet gave us Amazon and Google; mobile gave us Uber and Instagram. The prevailing narrative for AI was that it would similarly topple the old guard. Yet, three years into the generative AI boom, the biggest winners are the companies that were already dominant.
Why? Because AI, in its current form, is often a sustaining innovation rather than a disruptive one. For Google, AI makes search better. For Meta, it makes ad targeting more effective. For Microsoft, it makes coding in GitHub faster. These companies possess the two things startups lack: massive distribution and proprietary data.
Consider the "mobile search" analogy. When smartphones arrived, many predicted they would kill Google's web search monopoly. Instead, mobile search just became... search. The form factor changed, but the aggregator won. Similarly, while AI might change how we search or create content, it doesn't necessarily change who we do it with.
However, this safety is fragile. The danger for incumbents isn't that a startup builds a better model—models are becoming commodities. The danger is that AI fundamentally changes the nature of the product. If an LLM can answer a query directly, the list of blue links (and the ads between them) becomes obsolete. If AI agents start buying products for us, Amazon's recommendation engine loses its power. The incumbents are racing to cannibalize their own products before someone else does, leading to a chaotic environment where they must simultaneously defend their moats and blow them up.
The Interface Gap: Beyond the Chatbot
Part of the reason we see 900 million users but shallow utility is the interface. We are currently forcing users to be "prompt engineers," asking them to stare at a blinking cursor and figure out how to extract value.
This is a regression in user experience. The history of software is the history of reducing cognitive load. A Graphical User Interface (GUI) works because it constrains choices. When you open Salesforce or Photoshop, you aren't presented with a blank text box; you are presented with buttons, menus, and workflows designed by experts to guide you through a task.

From Prompts to Products: The evolution of AI requires moving from open-ended text boxes to structured, opinionated workflows.
The "chatbot" is a terrible interface for most complex work. It requires the user to know exactly what to ask and how to verify the answer. It is like having infinite interns: useful, but only if you spend all day managing them. The next phase of AI value creation will not come from better models, but from better wrappers—software that unbundles the "God in a box" into specific, reliable tools.
We are seeing this transition now. The "AI Lawyer" isn't a chatbot you argue with; it's a piece of software that automatically ingests discovery documents and flags contradictions. The "AI Architect" isn't a text prompt; it's a CAD plugin that optimizes floor plans. The winners of the next cycle will be the companies that figure out the "job to be done" and hide the AI behind a button that just says "Fix This."
The Fog of Scaling
Looming over all these strategic questions is a cloud of physical uncertainty. In the 1990s, we knew the theoretical limits of fiber optics. We knew how fast data could travel. With Large Language Models (LLMs), we are flying blind. We do not know if the current approach—throwing more data and compute at the problem—will continue to yield exponential gains, or if we are approaching a plateau.
Recent reports suggest that the "scaling laws"—the observation that performance improves predictably with size—may be hitting diminishing returns . The cost to train a frontier model has risen from $100 million to $1 billion, and soon to $10 billion. If the performance gains slow down, the economics of the entire industry must reset.
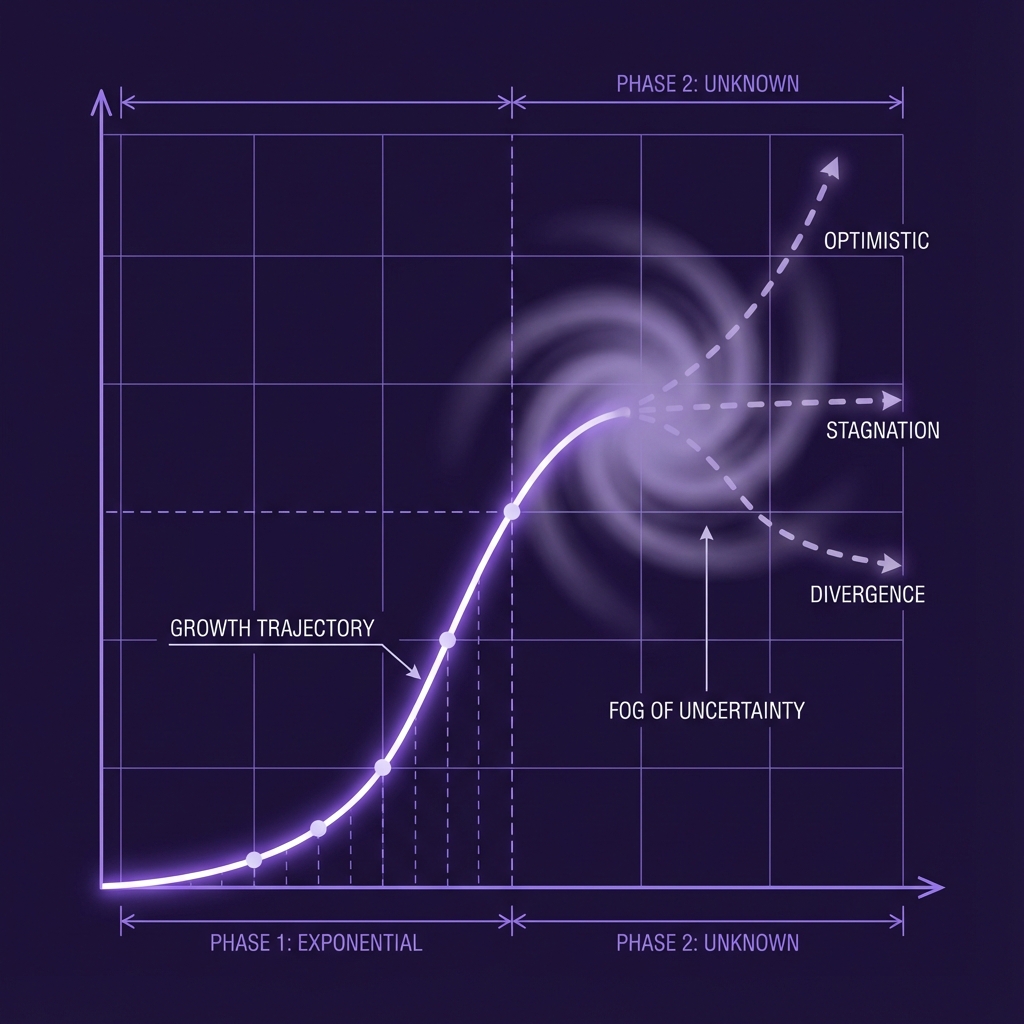
The S-Curve Mystery: Unlike Moore's Law or fiber optics, we do not yet know the physical limits of Large Language Model scaling.
This uncertainty is driving a shift from "training" to "inference." Instead of just making the model bigger, researchers are teaching models to "think" longer before answering (as seen in OpenAI's o1 series). This suggests a future where intelligence isn't just about static knowledge, but about the time spent processing a problem. It also implies that the hardware mix might shift, favoring chips designed for complex reasoning at the edge rather than just massive training clusters in the cloud.
Conclusion: The Unbundling of Intelligence
We are living through a moment of profound disconnect. We have technology that feels like magic, yet we struggle to apply it to the mundane. We have investment levels that rival the Manhattan Project, yet the killer app remains elusive for many.
This is typical of the "deployment phase" of any technological revolution. The electricity grid was built long before we figured out household appliances. The internet existed for years before we figured out e-commerce. The current AI bubble—if it is a bubble—is the mechanism by which the market funds the infrastructure that will eventually become invisible.
The question for the next few years is not "Is AI real?" The question is, "What is the software?" The companies that answer that—by turning raw intelligence into reliable, boring, indispensable products—will be the ones that survive the inevitable correction.
I take on a small number of AI insights projects (think product or market research) each quarter. If you are working on something meaningful, lets talk. Subscribe or comment if this added value.
Appendices
Glossary
- Hyperscalers: The massive technology companies (Amazon, Microsoft, Google, Meta) that operate the vast majority of the world's cloud computing and AI infrastructure.
- Inference vs. Training: Training is the computationally intensive process of teaching a model by feeding it data. Inference is the process of the model actually answering a user's question. The industry focus is shifting from training costs to inference costs.
- Scaling Laws: Empirical observations in AI research suggesting that model performance improves predictably as you increase the amount of data and computing power used for training.
Contrarian Views
- The Bubble Will Burst: Economists like Daron Acemoglu argue that AI will only automate a small fraction of tasks (approx. 5%) in the next decade, making the current valuation unsustainable.
- Data Wall: Some researchers believe we are running out of high-quality human text data to train models, which will force a hard stop on improvement regardless of compute spend.
Limitations
- User Data Reliability: The '900 million users' figure is self-reported by platforms or estimated by third parties; the definition of 'active' (daily vs. weekly) significantly alters the perceived utility.
- Future Uncertainty: This analysis assumes current trends in capex and scaling continue; a sudden breakthrough in model architecture or a global economic downturn could invalidate the 'over-investment' thesis.
Further Reading
- AI's $600B Question (Sequoia Capital) - https://www.sequoiacap.com/article/ais-600b-question/
- Gen AI: Too Much Spend, Too Little Benefit? (Goldman Sachs) - https://www.goldmansachs.com/intelligence/pages/gen-ai-too-much-spend-too-little-benefit.html
References
- Benedict Evans: AI Eats the World - A16Z Podcast (video, 2025-12-22) https://www.youtube.com/watch?v=lgZ7V-gQSeA -> Primary source for the 900M user claim, the 'God in a box' metaphor, and the comparison to previous platform shifts.
- The Future of Hyperscaler Capital Expenditures - Hyperframe Research (news, 2025-02-08) https://hyperframeresearch.com/hyperscaler-capex-2025-forecast/ -> Provides the $335 billion capex forecast for 2025, supporting the 'Infrastructure Casino' argument.
- AI's $600B Question - Sequoia Capital (org, 2024-06-20) https://www.sequoiacap.com/article/ais-600b-question/ -> Source for the revenue gap analysis and the economic requirements to justify current infrastructure spend.
- Gen AI: Too Much Spend, Too Little Benefit? - Goldman Sachs (whitepaper, 2024-06-27) https://www.goldmansachs.com/intelligence/pages/gen-ai-too-much-spend-too-little-benefit.html -> Contrarian view on the economic viability of generative AI and the productivity paradox.
- The Great AI Scaling Debate: Have We Hit a Wall? - Marketing AI Institute (news, 2024-11-19) https://www.marketingaiinstitute.com/blog/ai-scaling-laws-debate -> Discusses the potential plateauing of scaling laws and the shift in research focus.
- How Many Users Does ChatGPT Have? Statistics & Facts - SEO.ai (news, 2024-12-02) https://seo.ai/blog/chatgpt-user-statistics -> Provides context on user growth and the discrepancy between registered and active users.
- Beyond Bigger Models: The Evolution of Language Model Scaling Laws - Medium (Deval Shah) (news, 2024-10-01) https://medium.com/@devalshah1619/beyond-bigger-models-the-evolution-of-language-model-scaling-laws-3f5b966704c8 -> Explains the shift from training scaling to inference scaling (o1 models).
Recommended Resources
- Signal and Intent: A publication that decodes the timeless human intent behind today's technological signal.
- Thesis Strategies: Strategic research excellence — delivering consulting-grade qualitative synthesis for M&A and due diligence at AI speed.
- Blue Lens Research: AI-powered patient research platform for healthcare, ensuring compliance and deep, actionable insights.
- Outcomes Atlas: Your Atlas to Outcomes — mapping impact and gathering beneficiary feedback for nonprofits to scale without adding staff.
- Qualz.ai: Transforming qualitative research with an AI co-pilot designed to streamline data collection and analysis.